In this article I will explain what DBMS_PARALLEL_EXECUTE is and give an example of it’s use.
DBMS_PARALLEL_EXECUTE is an Oracle Supplied package which was introduced with Oracle Database 11g Release 2. It allows you to execute a SQL or PLSQL statement in parallel.
At a high level DBMS_PARALLEL_EXECUTE works by performing the following steps:
- Group sets of rows in the table into smaller sized chunks.
- Run a user specified statement on these chunks in parallel
The following example is based upon the one shown in the Oracle Documentation. One problem I found with that example was the calls to the DBMS_PARALLEL_EXECUTE sometimes had “mysterious” parameters that meant I needed to keep referring back to the documentation to find out what these parameters were.
The example that follows was built using the Oracle Developer Days Environment and used the following versions:
- Oracle Linux running via Oracle Virtual Box
- Oracle Database 11g Enterprise Edition Release 11.2.0.2.0
- Oracle SQL Developer 3.2.20.10
- The user developing and running the code is logged in as the HR user.
Set up
DBMS_PARALLEL_EXECUTE makes use of the Oracle scheduler so the system priviledge “Create Job” needs to be granted to HR. After logging in as a suitable user run the following command:
GRANT CREATE JOB TO HR
/
The example is based on a table I have created called EMPLOYEES2. Using a method described by Jonathan Lewis it populates the table with 5000 rows of random data.
Once the table has been created, a session_id column is then added. This will be used to keep track of which session performed the update.
CREATE TABLE EMPLOYEES2
AS
WITH v1 AS (SELECT ROWNUM N FROM DUAL CONNECT BY LEVEL <= 10000)
SELECT ROWNUM AS EMPLOYEE_ID,
DBMS_RANDOM.STRING ('a', 10) AS EMPLOYEE_NAME,
TO_DATE(TRUNC(DBMS_RANDOM.VALUE(2451911,2455928)),'J') AS HIRE_DATE,
trunc(dbms_random.value(10000,20000),2) as salary
FROM v1
WHERE rownum <= 5000;
ALTER TABLE employees2 ADD session_id NUMBER;
The final part of the set up is to create the procedure that will be invoked by DBMS_PARALLEL_EXECUTE. This updates the salary and session_id columns of the EMPLOYEE2 table. Note the use of the rowids within the WHERE clause.
CREATE OR REPLACE PROCEDURE update_emps
(
p_start_row_id IN ROWID,
p_end_row_id IN ROWID
)
IS
BEGIN
UPDATE employees2 e
SET e.salary = salary * 0.10,
e.session_id = sys_context( 'userenv', 'sessionid' )
WHERE e.rowid BETWEEN p_start_row_id AND p_end_row_id;
END update_emps;
Step 1 Create a task
The first step is to create a named task that will be referred to by later calls to DBMS_PARALLEL_EXECUTE.
BEGIN
dbms_parallel_execute.create_task
(
task_name => 'MyTask',
);
END;
/
Step 2 Dividing the table up
Next we create “chunks” of approx 1000 rows from EMPLOYEES2 table
BEGIN
dbms_parallel_execute.create_chunks_by_rowid
(
task_name => 'MyTask',
table_owner => USER,
table_name => 'EMPLOYEES2',
by_row => TRUE,
chunk_size => 1000
);
END;
/
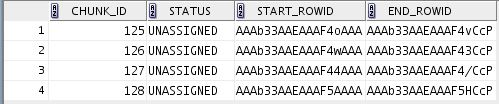
Querying the view user_parallel_execute_chunks enables us to view the chunks created.
SELECT chunk_id,
status,
start_rowid,
end_rowid
FROM user_parallel_execute_chunks
ORDER BY chunk_id

Step 3 Run Task
With the table “chunked” the task can now be run. In the call to dbms_parallel_execute.run_task, I have used the following values for the parameters
- sqlstmt: This a call to the procedure created during the setup. Note the use of the :start_id and :end_id. The statement used as a value for this parameter must have these place holders which become the rowid range to process.
- language_flag: This is set to native which according to the documentation “specifies normal behaviour for the database to which the program is connected”
- parallel_level: Specifies the number of parallel jobs.
BEGIN
dbms_parallel_execute.run_task
(
task_name => 'MyTask',
sql_stmt => 'BEGIN update_emps(:start_id, :end_id ); END;',
language_flag => DBMS_SQL.NATIVE,
parallel_level => 4
);
END;
/
When executed, dbms_parallel.run_task creates four jobs and each job will run the update_emps procedure against the chunk(s) assigned to it.
Step 4 Confirmation
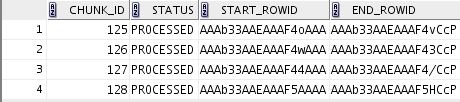
Once dbms_parallel_execute.run_task has finished, querying the user_parallel_execute_chunks view, shows the status of each chunk as PROCESSED.
If a chunk could not be processed or encountered an error, the status will be updated to PROCESSED_WITH_ERROR and the columns error_code and error_text from the same view will provide further information. Once the error(s) have been corrected you can run the task again to process the failed chunks.
SELECT chunk_id,
status,
start_rowid,
end_rowid
FROM user_parallel_execute_chunks
ORDER BY chunk_id

Querying the EMPLOYEE2 table confirms that the job was completed using parallel 4 along with the number of rows updated by each session.
SELECT session_id,
COUNT(*)
FROM employees2
GROUP BY session_id
ORDER BY session_id
Summary
In this article I have given an overview of DBMS_PARALLEL_EXECUTE along with an example of its use.
Acknowledgements and Sources:
Tom Kyte’s superb book Expert Oracle Database Architecture 2nd Edition. The section on DBMS_PARALLEL_EXECUTE is available on the Ask Tom website.
The Oracle Database Documentation on DBMS_PARALLEL_EXECUTE.

How to execute a stored procedure or stored function using DBMS_PARALLEL_EXECUTE.
Example :
I have a table say employee, with employeeid column and few other fields. Now I want to run a procedure name “myprocedure” for each and every employeeid.
myprocedure defination is as below:
myprocedure(employeeid, runDate, runUserId, settlementsdays,…);
myprocedure is a very complicated procedure with thousands of line and may calls to other procedures.
HELP PLEASE…
Hi,
Thanks for your question,
To be able to answer such a question more information is required than you can put in the comments on this blog. I suggest you ask this question on Stackoverflow
Thanks again.